★★★ Access2000VBA・Excel2000VBA独学~Excelに、テキストファイルの内容を、「SQLを使いながら」・かつ・「絞り込みながら読み込む」方法(QueryTableオブジェクトにてODBC接続利用)※ADO+OLEDBは別です。~
※まだ書きかけです。すみません。
※間違ってたらすみません。
※メモ書きなので、自分でも意味不明な箇所も多いです。ごめんなさい。
※関連Web記事
『 ADOでCSVの読み込み(SQL) 』
『 VBAでのCSVの扱い方まとめ(文字コードがどうしても関係する場合とか) 』
目次
★ はじめに
★ テキストファイルを「 ” SQL ” を使いながら」吸い込みたい場合の注意・事前知識
★ テキストファイルごとの、吸い込み設定の具体例
★ 「ODBCデータソース」を作ると、例えばMicrosoft Queryからはどう見えるか?
★ ExcelのMicrosoftQueryのウィザード画面のデータソースの一覧での、「*」の意味
★ 先にSchema.iniとフォルダ、テキストファイルを作ってから、
ODBCデータソースアドミニストレータに登録するとどうなるか?
★ 先にSchema.iniとフォルダ、テキストファイルを作ってから、
ExcelのMicrosoftQueryのウィザード画面のデータソースに登録するとどうなるか?
★ 「ODBCデータソース」を作ると、VBAからはどう扱えるようになるのか?
★ テキストファイルを置くフォルダを作成
★ そのフォルダを「ODBCデータソース」のひとつとして設定する
(複数のテキストファイルを置けますし、区切り文字なども別々に設定できます。)
★ そのフォルダを「ODBCデータソース」のひとつとして設定するできます。)
★ そのフォルダに、カンマ区切りのテキストファイルを配置
★ カンマ区切りのファイルの列名行の指定や区切り文字等々の設定
★ そのフォルダに、スペース区切りのテキストファイルを配置
★ スペース区切りのファイルの列名行の指定や区切り文字等々の設定
★ Microsoft Queryからカンマ区切りのテキストファイルを読み込んでみる
★ それをマクロの記録にしてみる(QueryTableオブジェクトのみ)
★ 同上(ListObjectつき)
★ VBAを書き換えてスペース区切りのテキストファイル吸い込んでみる。
★ VBAのSQLを書き換えて、絞り込んでみる
★ マクロで生成されたプログラム例:バージョン2010の場合(このコードだとカンマ区切りしか吸い込めませんでした)
★ C:\USERS\USER01\DESKTOP\ttt.txt の中身の例
★ Excel2000の場合01(2010でのコードをまんまで使ったテスト)
★ Excel2000の場合02
ExcelVBAの「QueryTableオブジェクト」でテキストファイルを読み込む場合、多くが・・・
========================================
Set a = ActiveSheet.QueryTables.Add( _
Connection:="TEXT;C:\フォルダ名\テキストファイル名.txt", _
Destination:=Range("$A$1"))
・・・以下云々
※参考URL
https://excel-ubara.com/excelvba5/EXCEL111.html
引用:「文字コードがUTF8の場合 .TextFilePlatform = 65001 'UTF8 このように、932の代わりに65001を指定してください。」
========================================
・・・というような感じのコードで吸い込む形となると思います。
Web上にもこの形での紹介が多いです。
『 リボン → データ・タブ → テキストファイル・ボタン(「外部データの取り込み」グループ)』での吸い込みと同じ動きになりますよね。
でも、このやりかたですと、どうやら、ですが、「テストファイルが1つだけ吸い込める」ってだけで、SQLが使えないもようなのです。(検索不足でただ単に分からなかっただけかもしれませんが。僕はバカなので、ヘルプやWebサイトをいろいろ探したんですが分かりませんでした。)
もちろん、吸い込んだデータは、「全行・全列」が「ドバン!!!」と吸い込まれてしまいます。めんどくさっ!
しかもたった一つのテキストファイルだけしか吸い込めない!!めんどくさっ!
「SQLで絞り込みしながら吸い込む」なんてできやしません。めんどくさっ!
もちろん、複数のテキストファイルをリレーションさせながら・・・もできません。
あ~・めんどくさっ!
それを避けたくて、「テキストファイルを吸い込みつつ、でもそれに対してSQLも使いたい・リレーションも組みながら吸い込みたい」という場合は、ODBCドライバ経由(ODBCデータソース経由)などならできるっぽいです。(以下の参考Web記事をご参照ください。)
参考Web記事
『ODBCのText DriverとExcelとを使ってCSVファイルをSQLで検索・抽出する』
※↑「注意しなければならないのは、、、」のところを必ず読んでおいてください。
というわけで、実際に上記記事のようにやってみましたら、「結構便利かも?」と感じましたので、やりかたをメモっておこうと思います。
※もしかしたらですが、SQLが使える、ということはテキストファイルの内容もSQL+ODBC経由でレコードの追加・編集などもできるかもしれません。Excelファイルが対象の場合ではSQLでは削除だけができませんが、テキストファイルならSQLで削除もできるのかも???でも、未確認なのでご自分でも調べてみてください。
※光栄にも、『 https://qiita.com/Q11Q/items/9c93552a0efd49d06fc4 』というWebページにて、「こんなバカが書いている情報は信用ならない」とお褒めの言葉をいただきました。
そうです。
この方の言う通りです。
なので、当記事はもちろん、ぼくのサイトの情報は全部、信用しないでください。
全部、「テキトー」ですから。
必ずご自分でもしっかりと色々とお調べくださいね。
※更にもしかしたらですが、2010?2013?以降の、パワークエリやパワーピボットなどでも、「テキストファイルを ” SQLを使いながら・リレーションを組みながら ” 吸い込む」ということが可能かもしれません。が、ODBCデータソース経由でMicrosoftQueryやVBAで扱うほうが、多分ですが、はるかに、ラクちんだとは思います。古い技術なので余計なことを覚えなくていいからです。いずれにしましても、パワークエリやパワーピボットなどでもできるのならそちらを使ってもいいと思います。パワークエリやパワーピボットにしかない、便利な吸い込み機能もあるかもしれませんので。クラウド対応とか。
なお、「ODBCデータソース」というものは、「ODBCデータソースアドミニストレータ(32bit Or 64bit」で作成するのですが、そのツールはWindows95以降(多分)、98、2000、XP、Vitsta、7、8、10、すべてのOSで使えるOS標準の機能です。
(Windows95、98、あたりは、もしかしたらSchema.ini(後述)が別のファイル名かもしれませんが、 『Microsoft Jet データベース エンジンとODBCとレジストリとSchema.ini 』を見ると、95や98もSchema.ini が使えるのかもしれません。)
★ テキストファイルを「 ” SQL ” を使いながら」吸い込みたい場合の注意・事前知識
※参考Web記事
『データ ソース (ODBC) ※機械翻訳?』
『Microsoft Jet データベース エンジンとODBCとレジストリとSchema.ini 』
テキストファイルを読み込むときに・・・
(a)SQLを使いたい。
(b)SQLを使って、絞り込みをしながら、テキストファイルの内容を吸い込みたい。
(c)一般的な「テキストファイルのインポート」機能は必ず全てのデータが吸い込まれてしまい、「SQLでの絞り込みができない」ので面倒くさくて使いたくない。
(d)「ADO+OLEDB接続+Range.CopyFromRecordsetメソッド」でもやれるけど、それだと「列名表示専用」のコードが追加(別途)で必要でいちいちそんなことするの面倒くさい。
(e)「ADO+OLEDB接続+Range.CopyFromRecordsetメソッド」の場合、結果の表を操作する際に、「手軽な」「右クリックで ”更新” できる」、そういうメニューが「無い」ので、それも面倒くさい。
(f)「QueryTable+ODBC接続」でなら、そんな面倒も無いので(列名専用コードなんか要らないし、右クリック更新も可能だし、速度も配列利用に負けないくらいなので)ODBC接続でやりたい。
(g)吸い込むテキストファイルの種類や各フィールドの型も細かく指定したい
・・・というような場合は、事前に・・・、
・そのテキストファイルを格納しているフォルダと、
・その吸い込みたいテキストファイルそのものに対して、
・「ODBCデータソース」というものを、事前に、設定しないとやれないっぽいです。
なお、「ODBCデータソース」は、設定1個あたりにつき、「テキストファイルを置くフォルダと、その中に置くテキストファイルそのものの両方」に対して設定します。
「ODBCデータソース」は、(CSVやテキストファイルの場合は)「フォルダ単位」でのデータソースの設定となります。
「ODBCデータソースアドミニストレータ(32bit Or 64bit」で作成しますが、そのツールはWindows95以降(多分)、98、2000、XP、Vitsta、7、8、10、すべてのOSで使えるOS標準の機能です。
(Windows95、98、あたりは、もしかしたらSchema.ini(後述)が別のファイル名かもしれませんが、 『Microsoft Jet データベース エンジンとODBCとレジストリとSchema.ini 』を見ると、95や98もSchema.ini が使えるのかもしれません。)
基本、「ODBCデータソース」としてのフォルダを1つ決めれば、その中に、「カンマ区切り」「タブ区切り」「カスタム区切り(スペースやアンダーバーなどでの独自の区切り)」、さまざま区切りのテキストファイル(CSVなども含む)を置くことができます。
そして(SQLを使っての)、それらのファイルの内容の吸い込みができます。(あくまでも「表データ」として、ですが。)
そしてそれらのファイル同士で(関連性があるもの同士なら)、リレーションも組めます。
※「ODBCデータソース」は前述のとおり、テキストファイルの場合に限って言えば、「フォルダ単位=フォルダごと」に、個々に、設定ができます。基本、好きな名前を付けて設定ができます。
なので、「テキストファイル専用のフォルダとして・1つだけしか設定が作れない」というわけではありません。いくつでも、「フォルダの数だけ(そしてその中の個々のテキストファイルに対して)」、作れます。
●「ODBCデータソース」を作成する画面(「GUI」の画面:ODBCデータソースアドミニストレータ。)
(コントロールパネル→管理ツール→ODBC データ ソース (×× ビット))
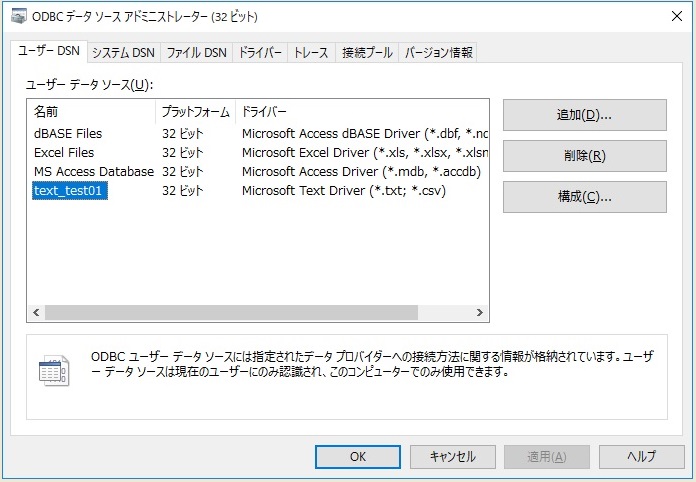
●テキストファイルごとの「吸い込み設定(詳細は後述)」の画面(同じくODBCデータソースアドミニストレータ、の一部。)
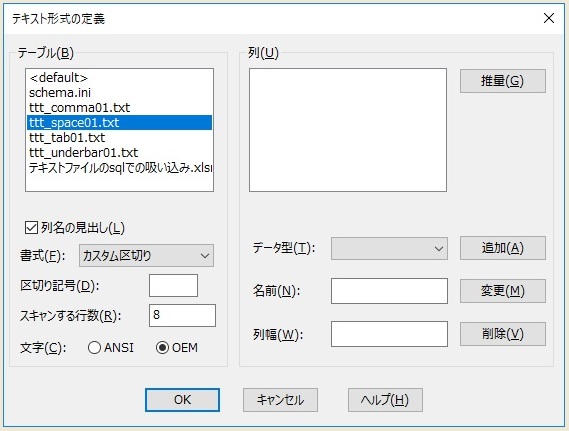
そして、それらの個々のファイルにはそれぞれ個別に、「ODBCデータソース」の設定の中で、「吸い込み設定(具体例は後述)」をします。
以下のようなものを設定できます。(上図「テキストファイルごとの設定画面」を参照)
・「書式(カンマ、タブ、カスタム、どれで区切るか?の設定)」、
・「カスタム区切りの場合の区切り文字
(スペース、アンダーバーなどを区切り文字に設定できます)」、
・「スキャンする行数(多分、各列のデータ型が揃っているかのチェック含め)」、
・「1行目を列名とするかどうか(列名の見出し設定)」、
・「文字コード
(ANSIかOEMかの設定。ただし、以下のようなことのようです。)」、
※引用・・・米国を含む多くの 1 バイトコードを常用している国では,歴史的理由から
Windows 環境下の文字セットとファイルシステム上で使用される文字セットが
異なる場合があります。Windows 上の文字セットを ANSI 文字セットと呼び,
動作環境に固有の文字セットを OEM 文字セットと呼ぶ場合があります。
DOS 環境で作られたファイルと扱う場合に ANSI - OEM 変換が必要になる場合
があります。日本語環境においては Windows 環境の文字セットと環境固有の
文字セットは両方とも Shift-JIS である場合がほとんどなので,
ANSI-OEM 変換は意味を持ちません。
※ここでは詳しくやっていませんが、
「列」単位のデータ型の設定などもできるようです。
そしてその設定は、ADO+ODBC??でも使えるっぽいです。
http://blog.livedoor.jp/tea_cocoa_cake/archives/7152895.html
https://ameblo.jp/catsliving-se/entry-10519964022.html
引用『 ~~自動的に使用される。上記のVBScriptコードのように、
ADOを使ってテキストファイルにアクセスする時は「どのSchema.iniを参照するか」
という指示はコード上のどこにも書かない。』
・・・というわけで、どうやら少しラクちんっぽいです。(^^)
これらの項目は、「テキストファイルのインポート(テキストファイルのみに特化した吸い込み機能)」の操作をVBA化した際は、そのVBAコードの中で書いて設定しますが、「SQLを使いたい場合+ODBCデータソースでやりたい場合」は、VBAコードの中にはこれらの項目の設定は書きません。
事前に、「ODBCデータソース」の中で設定します。
なお、その「吸い込み設定」の具体的な内容は、「ODBCデータソースの作成のときに指定したフォルダ」の中の「schema.ini」というテキストファイルの中に全部書き込まれます。
「schema.ini」は、「ODBCデータソースを作成した瞬間」に、自動的に対象のフォルダの中に自動生成されます。
ODBCデータソースの設定が完了したフォルダの例(「schema.ini」ができています。)
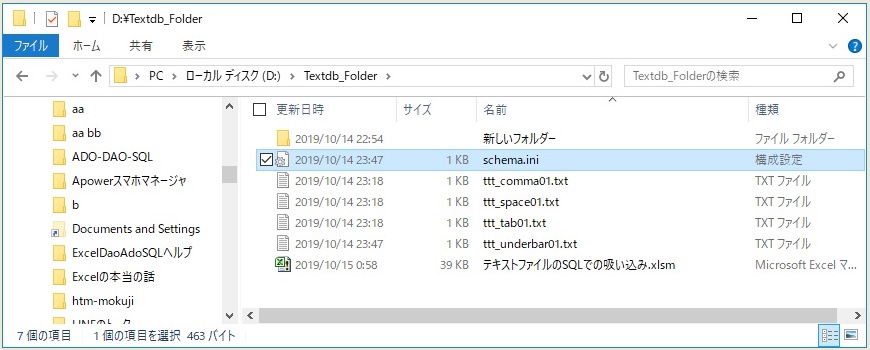
個々のテキストファイルの吸い込み設定は、「schema.ini」の中に書かれています。中身については後述。)
「schema.ini」は、いちど自動生成されれば、たとえばのちのち、吸い込みたいテキストファイルやCSVなどが新たに出てきた場合、その「schema.ini」に吸い込み設定の内容を書き足せば(コピペしてほんの少し編集、でOK)、GUIの設定画面を使わずとも、吸い込み設定の追加設定が終わります。
そして、GUIでの設定画面側(=前述の「ODBCデータソースアドミニストレータ」の側)にも、その追加した吸い込み設定の内容が、自動的に表示されるようになります。
★ テキストファイルごとの、吸い込み設定の具体例
なお、「schema.ini」には、例えば以下のような感じで、吸い込む対象とするテキストファイルごとに設定エントリが書き込まれます。(メモ帳で開くと見ることも書き換えすることもできます。)
[schema.ini] ←ファイル名指定ではなく、「デフォ設定」、の意味
ColNameHeader=False
Format=CSVDelimited ←デフォの区切りの種類は「カンマ区切り」で、区切り文字は「半角カンマ」
MaxScanRows=25
CharacterSet=OEM
[ttt_space01.txt] ←個別・特定のテキストファイル名 ※(個別設定の最初の行)
ColNameHeader=True ←1行目を「列名」にする
Format=Delimited( ) ←区切りの種類は「カスタム区切り」で、区切り文字は「半角スペース」
MaxScanRows=8 ←スキャンする行数
CharacterSet=OEM ←文字コード ※(個別設定の最後の行)
[ttt_tab01.txt]
ColNameHeader=True
Format=TabDelimited ←区切りの種類は「TAB区切り」で、区切り文字は「TAB」
MaxScanRows=8
CharacterSet=OEM
[ttt_underbar01.txt]
ColNameHeader=True
Format=Delimited(_) ←区切りの種類は「カスタム区切り」で、区切り文字は「アンダーバー」
MaxScanRows=8
CharacterSet=OEM
「schema.ini」というファイルをメモ帳で開いて、以下のような設定エントリ(ファイル1個分)を追加で書き込むと、GUIの画面の側に、この内容が勝手に反映されます。(なので、コピペしたあとにファイル名だけを変えてもOKです。もちろん、事前に、ODBCデータソースのフォルダに、その設定に対応するテキストファイルが格納されている必要があります。)
以下、テキストファイル1個分の設定内容の例。
この例だと「ttt_space01.txt」というテキストファイルの吸い込み設定を追加できます。
[ttt_space01.txt] ←個別・特定のテキストファイル名
ColNameHeader=True ←1行目を「列名」にする
Format=Delimited( ) ←区切りの種類は「カスタム区切り」で区切り文字は「半角スペース」
MaxScanRows=8 ←スキャンする行数
CharacterSet=OEM ←文字コード
(※このようなものをとりあえず、コピペして必要箇所を書き換えればOKです。大抵は、ファイル名と区切り文字のところだけでOKかと思います。フィールドごとの細かい設定もしたかったら、すぐ下の『 ※参考Webページ:「Schema.ini ファイル」での各種設定についての詳細。』のURLをご参考にしてください。)
下図のように、GUIの設定画面に出てきます。(下図の中の青く選択されたもの、のように。) ※GUI画面の区切り文字の設定は、空白のように見えますが実際には半角スペースが入力されています。
※参考Webページ:「Schema.ini ファイル」での各種設定についての詳細。(記事を書いた後に「CSVDelimited」でWeb見てたらたまたま見つかりました!)
『スキーマ ファイルの定義』
『テキスト ファイルのフィールドを定義する方法 』
『Schema.ini ファイル (テキスト ファイル ドライバー)(機械翻訳?)』
『schema.iniファイルを利用してテーブルの定義情報通りに読み込む (TAB区切りのテキストファイルを読み込む) 』
★ 「ODBCデータソース」を作ると、例えばMicrosoft Queryからはどう見えるか?
例えば「text_test01」という名前の「ODBCデータソース」を作った場合に、Microsoft Queryの操作途中のダイアログ画面で、それがどう見えるかの図を示します。下図のようになります。(青く選択されたところが「text_test01」という名前の「ODBCデータソース」です。)
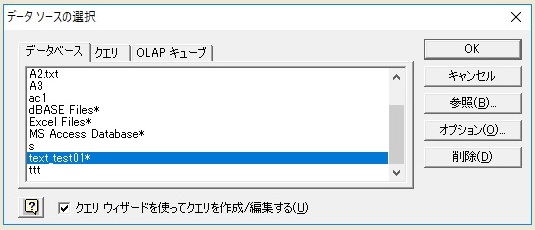
上図は、例えばバージョン2010の場合なら、「データ→その他のデータソース→Microsoft Query」とたどると出てきます。
Excelファイルのデータを読み込みたいときはここでExcelファイルを指定するのですが、テキストファイルの場合は上図のように作成したODBCデータソース名を選びます。(もし事前に複数のODBCデータソースを作った場合は、そのすべてが、ここに表示されます。MicrosoftQueryは基本、「ODBC接続」が使われるっぽいです。)
このあと、下図のように、フォルダ内のテキストファイルたちを選択できるようになります。
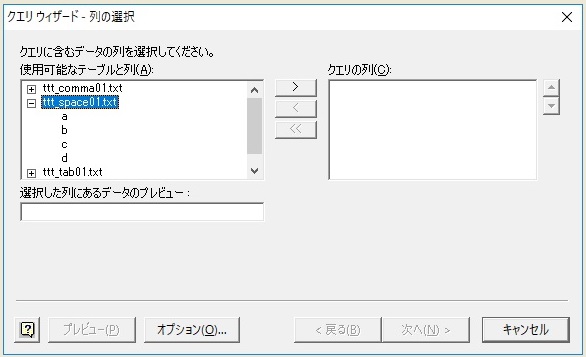
(※このダイアログの中には、ODBCデータソースの設定をしたフォルダ内のすべてのテキストファイルが表示されます。ただし、「未設定のものや設定に失敗しているもの」もとりあえず表示されてしまいます。そこはご注意ください。Microsoft QueryやVBAで扱えるのは、表示されたテキストファイルのうち、GUI画面=ODBCデータソースアドミニストレータの画面かSchema.ini ファイルにて、正常に設定が完了したもののみです。もちろん、カンマ区切りなどはデフォなので設定は不要ですが。)
これで、全列×全行をバンっ!!!と全部吸い込むことも、データを絞り込みながら吸い込むことも、思いのまま、です。
もちろん、テキストファイル同士が関連性のあるファイル同士なら、リレーションも組めます。
よって、『 関連ファイルごとに、複数のフォルダでそれらを分けてまとめて、それらごとに、複数のODBCデータソースを作る・・・』、あるいは、『 1つのフォルダだけをODBCデータソースにして、あとはテキストファイルの名前にプレフィックス(接頭語・接頭辞)を付けてまとめる・・・』、など、ケースバイケースで色んな管理方法が考え付くと思います。
★ ExcelのMicrosoftQueryのウィザード画面のデータソースの一覧での、「*」の意味
「*」がついているのは、多分ですが、『 GUIの「ODBCデータソースアドミニストレータ」の画面に登録されているかどうか? 』か、ExcelやAccessにも「*」が付いていますので、『 OSが公的に認識しているか?』みたいな感じも意味しているような気がします。
理由は、Schema.iniは、例えば、ExcelのMicrosoftQueryのウィザード画面にて、直接このダイアログの最上行の「<新規データソース>を選択してOKした画面」でデータソースを作った場合にも、その時に『 データソースとして指定したフォルダ 』の中にも自動生成され、かつ、データソースフォルダとして登録されるからです。
でもって、そのときに「*」は付きません。
にもかかわらず、「*」の付かないそのデータソースのフォルダに、『 新しいテキストファイルとそれに対応するSchema.iniの設定 』を追加すると、そのファイルもモトからあったテキストファイルも、両方を読めるようになります。
もちろん、そのファイルたちが関連性のある者同士なら、リレーションも組めます。
だから、です。以上が理由です。多分・・・ですけど・・・。
以上のようなことから、『 Schema.iniは、見た目的に GUIの「ODBCデータソースアドミニストレータ」の画面に登録されていないっぽい場合でも、Excel(MicrosoftQueryなど含め)から見た場合は有効 』とも言えるようです。
★ 先にSchema.iniとフォルダ、テキストファイルを作ってから、ODBCデータソースアドミニストレータに登録するとどうなるか?
データソースの名前とフォルダを指定しただけで、あとは何もしなくてもテキストファイルの細かい「吸い込み設定」が認識されます。Schema.iniに書いたとおりに。
★ 先にSchema.iniとフォルダ、テキストファイルを作ってから、ExcelのMicrosoftQueryのウィザード画面のデータソースに登録するとどうなるか?
この場合、MicrosoftQueryのウィザードのダイアログ画面(前々々項の画面)のリストにて、その最上行の「<新規データソース>を選択してOKして」、データソースを作る=フォルダ指定をすることになります。
そして、こちらの場合も、データソースの名前とフォルダを指定しただけで、あとは何もしなくてもテキストファイルの細かい「吸い込み設定」、あるいは「吸い込み用フォルダ」として認識されます。
で、この場合は「*」は付きませんが、でも「吸い込み用フォルダ」として認識されますので、ExcelのMicrosoftQueryのウィザード画面のデータソースに登録する際に、付ける名前は「×××フォルダ」とか「×××関連」、「×××管理」といったような名づけをした方がいいのかもしれません。
★ 「ODBCデータソース」を作ると、VBAからはどう扱えるようになるのか?
もちろん、VBAからもQueryTableオブジェクトを通じて、操作できるようになります。(VBAでは上図のような画面は出ませんが。)
その場合、ODBCデータソースを指定する形でVBA操作しますので、VBAコード上では『 区切り文字や列名設定(1行目)などの設定 』は書きません。(それらは全部、「ODBCデータソース」の中に入っているため。=多分、「schema.ini」の中に既に書かれているため、ODBCデータソースという機能がそれを読みに行ってくれるから・・・みたいなイメージだと思います。)
※★★注意!!
Microsoft QueryとQueryTableオブジェクトは、両方とも「ODBC接続で処理できるため」似てはいますが、でも「似て非なるもの」ではあります。
MicrosoftQueryとQueryTableオブジェクトはお互い、「独立した機能」で、「Microsoft Query」はGUI画面中心でSQLを操作する機能で、QueryTableオブジェクトはVBAにて文字だけでSQLを操作する機能です。
また、『 Microsoft Query(GUI)で行った集計や抽出の結果を返す=結果を表示する場所が、QueryTableオブジェクト・・・』というイメージです。
なお、「 Microsoft Query(GUI)」は、Accessの「クエリ」という機能と酷似しており、 Microsoft Query が扱えれば、Accessのクエリも入りやすくなるので、練習になります。また、SQLを扱うこと自体も、他のデータベースソフトに少し入りやすくなりますし、VBAだけができるよりも重宝がられますし、昇給を自分から申し出ても恥ずかしくないくらいです。(「VBAの無駄なループ処理」や「無駄なワークシート関数」を半分以下にしたり、複雑な条件での集計や記録がVBAよりも安く・早く出せるため)。
基本、ExcelでのSQLの「書き方」には少し「独自ルール」があって、「Microsoft Query」でもVBAでも「共通に使えるSQLの書き方」、というものが存在します。その独自ルールから逸脱すると、VBA側ではSQLが使えても「Microsoft Query」画面では「SQL文の内容のエラーで開けない」、ということが起こります。それを避けるには、以下の記事をご参考にしてみてください。
『★★★Access2000VBA・Excel2000VBA独学~「QueryTableオブジェクト」~~「VBAプログラム」からも、「MicrosoftQueryの画面」からも操作が可能となる、そのための「VBAからのSQLの書き方」や「前提条件」など(概要説明のみ)~』
あと、テキスト吸い込みの話からは外れますが・・・、MicrosoftQueryで行った集計や抽出結果は、バージョン2000~2003までは、直接QueryTableオブジェクトに返されますが(表示されますが)、2007以降は、「テーブル機能(ListObjectオブジェクト)」の中にいったん埋め込まれた「QueryTableオブジェクト」の中に表示されます。また、自Excelファイルの中を覗くとエラーになることがほとんどです。(細かいところは未確認です。)
でも、MicrosoftQueryを使わずに、直接、VBAにてQueryTableオブジェクトを使うと、2007以降でも「テーブル機能(ListObject)」の中に埋め込まれることなく、直接「QueryTableオブジェクトだけを」ワークシートに表示させて操作できます。
また、その場合は、自Excelファイルをどのように覗きに行ってもエラーになりません。さらには、自ファイル内で結果の結果の結果・・・・のようにネスト的なこともできます。
これができると「かなり複雑な条件であっても、我々ド素人でもなんとか結果を出せる」ため、本当に便利です。
Accessにおける「クエリをモトにしたクエリをモトにしたクエリ・・・」というようなことができるわけです。
自由度が大きいです。
「テーブル機能」がSQL結果の出力先だと、そういうことがまったくできなく、効率が悪いと言えば悪いです。(もちろん、1段階のみ・かつ・テーブル機能の機能だけを使いたい・というだけなら効率が悪くはなりませんが)
では、以降、「QueryTableオブジェクト+ODBC接続」の簡単な例を示します。
【例01】
『 事前に「text_test01」という名前のODBCデータソースを作った場合 』に、それを使う設定をVBAで書いた場合の例、です。
VBAでは以下のような形で、ODBCデータソースとSQLを指定します。
(SQLの指定には「QueryTableオブジェクト」の「CommandTextプロパティ」あるいは、「SQLプロパティ」を使います。)
すると、テキストファイルを吸い込むときに、VBAコード内で「SQL」を使えるようになります。
こちらも、Microsoft Queryの時と同様に、全列×全行をバンっ!!!と全部吸い込むことも、データを絞り込みながら吸い込むことも、思いのまま、です。
もちろん、テキストファイル同士が関連性のあるファイル同士なら、リレーションを組みながら吸い込むことも可能です。
Dim QTbl01 AS QueryTable
Set QTbl01 = ActiveSheet.QueryTables.Add(Connection:= "ODBC;DSN=text_test01; DefaultDir=D:\Textdb_Folder;DriverId=27;FIL=text;MaxBufferSize=2048;PageTimeout=5;" , Destination:=Range("A1"))
QTbl01.CommandText = Array("SELECT * FROM ttt_tab01.txt ttt_tab01")
・
・(以下略)
・
上記の例では、「DSN=text_test01」が『 「text_test01」という名前のODBCデータソースを使用しますよ~! 』という意味で、ODBCデータソースの指定設定です。
そのほか、「DefaultDir=D:\Textdb_Folder」がそのODBCデータソースで設定したフォルダです。
区切り文字や列名などの「具体的な吸い込み設定」は、「text_test01」というODBCデータソースの中ですでに(テキストファイルごとに)設定がなされているわけで、で、上記コードではそれを選択=指定したわけですので、VBAコードとしては、「具体的な吸い込み設定」は特に何も書く必要がありません。
他の、テキストファイル用のODBCデータソースの場合も同じルールです。
【例02】
★以下の例では、上記の【例01】を使って、実際に、D:\1フォルダに対して「d1」というODBCデータソースを設定し、利用しています。Win11+Excel365(当時2021)でも動きました。もちろん、Win2000+Excel2000などの古いバージョンでも動きます。
★文字コードがUTF-8やUnicodeの場合、この「ODBCデータソースを使う方法」だと、「.TextFilePlatform」プロパティを使ってもエラーになってしまうようなので、
CSVををShift-JISの文字コードに変化してからじゃないとダメみたいです。
あるいは、ACEエンジンを使ってADOで文字コードを設定してSQLで吸い込むか、
はたまた、いったん単なる「テキストインポート」で文字コードを指定しながら
Excelに吸い込んで、そのあとSQLを使う・・・、などです。(他の代替案もあるかもしれません)
同じQueryTableを使うのでも、単なる「テキストインポート」の動作のほうのQueryTableの動きなら、「.TextFilePlatform」プロパティが使えます。
本当は「ODBCデータソースを使う方法」においても、文字コードを設定できるのかもしれませんが(Schema.iniをいじるとか?)・・・。
なお、Excel2007のヘルプでは「TextFilePlatform」の定数は「XlPlatform クラス」の「xlMacintosh(1)、xlMSDOS(3)、xlWindows(2)」の3つで、「Shift-JIS(932)、UTF-8(65001)、UTF-16(1200)」ではないので、これもナゾの1つです。
※UTF→S-JISの自動変換(VBAコード)の例
このページの一番下にサンプルプログラムがあります。
以下はそれと同じ内容の別ページです。↓
https://euc-access-excel-db.com/tips/ct07_se/ct075012_xls2k_vba_tips/textfile_utf8_to_shiftjis01
★今回の記事の中でも、一番シンプル、かつ、多分異なるOfficeバージョンやOSバージョンの間でもエラーが出ないコード、だと思います。(後述の2010のODBCソース名を使わないものは、OSやOfficeのバージョン、ODBC設定などによってはエラーが出ます)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
' ' Sub Macro4() 'OK。Win11+Excel365(当時2021)でも動いた。 ' Dim o_QTbl01 As QueryTable Dim s_ODBCsrcName As String Dim s_ODBCsrcPath As String Dim s_SqlStr As String Dim s_RngName As String s_ODBCsrcName = "d1" 'OSの「ODBCデータソース」の画面で設定した「データソース名」 s_ODBCsrcPath = "d:\1" 'その「データソース名」のデータソースのフォルダのパス ' s_SqlStr = "SELECT * FROM [aaa.csv] as csv1 inner join [bbb.csv] as csv2 on csv1.f01 = csv2.f001" s_SqlStr = "SELECT f03, f001 FROM [aaa.csv] as csv1 inner join [bbb.csv] as csv2 on csv1.f01 = csv2.f001" s_RngName = "d1からのクエリ" '名前の定義での名前 '空のQueryTableオブジェクトの生成(ODBCデータソース利用) Set o_QTbl01 = ActiveSheet.QueryTables.Add( _ Connection:= _ "ODBC;DSN=" & s_ODBCsrcName & ";" & _ "DefaultDir=" & s_ODBCsrcPath & ";" & _ "DriverId=27;" & _ "FIL=text;" & _ "MaxBufferSize=2048;" & _ "PageTimeout=5;", _ Destination:=Range("A1")) '空のQueryTableオブジェクトへの、SQL結果の「表」の表示。 With o_QTbl01 ' .CommandText = Array("SELECT * FROM [aaa.csv] as csv1 inner join [bbb.csv] as csv2 on csv1.f01 = csv2.f001") .CommandText = Array(s_SqlStr) ' .Name = "d1からのクエリ" .Name = s_RngName .FieldNames = True .RowNumbers = False .FillAdjacentFormulas = False .PreserveFormatting = True .RefreshOnFileOpen = False .BackgroundQuery = True .RefreshStyle = xlInsertDeleteCells .SavePassword = True .SaveData = True .AdjustColumnWidth = True .RefreshPeriod = 0 .PreserveColumnInfo = True .Refresh BackgroundQuery:=False End With End Sub ' ' |
★注意01!!!!!!!
上記の例は、「d1」ODBCデータソースの中の、CSVファイルを操作の対象にしているわけなんですが、CSVの場合、かつ、「Inner Join」句でリレーションを組もうと思うと、テーブルを「AS ×××」で別名を付けないとON句でエラーになってしまうみたいです。
逆に、「WHERE」句でリレーションさせる場合(オラクル方式?)は別名は要らないようなのですが・・・。
例えば、
SELECT * FROM [aaa.csv] as csv1 inner join [bbb.csv] as csv2 on csv1.f01 = csv2.f001
を
SELECT f03, f001 FROM [aaa.csv], [bbb.csv] WHERE f01 = f001
と「WHERE」句でのリレーションのSQLに書き換えるとOKなんですが・・・・、
それを、
SELECT * FROM [aaa.csv] inner join [bbb.csv] on [aaa.csv].f01 = [bbb.csv].f001(SQL構文エラー)
とか
SELECT * FROM [aaa.csv] inner join [bbb.csv] on f01 = f001(一般ODBCエラー)
と書くと、それぞれカッコ内に書いたエラーになります。
また、
SELECT * FROM [aaa.csv] as csv1 inner join [bbb.csv] as csv2 on f01 = f001
と書いても(一般ODBCエラー)になります。
「一般ODBCエラー」のほうは「構文は間違ってないけど処理できない」ってことなんでしょうか???
ナゾです。
ExcelのSQLは最後の「;」が無くてもOKなのですが、これらの場合は「;」を付けてもエラーになります。
xlsやxlsxで1つのブック内の2つのシートでリレーションを組む時は、このエラーにはならないのではないかと思いますが・・・。
※→チェックしたらやはりOKでした。xlsでもxlsxでもOKです。
例→SELECT * FROM [aaa$] INNER JOIN [bbb$] ON [aaa$].f01 = [bbb$].f001
ON句にテーブル名がないとエラーになりますが、別名は不要でした。
また、一部のWebサイトにxlsxには使えないと書いてありますが、
それは間違いのようです。
★注意02!!!!!!!
Excelの場合、WHERE句での結合は内部結合のみで、外部結合はできないっぽいです。
もしかしたら、何かやり方があるのかもしれませんが現時点では不明です。
一応、「*」や「(+)」を使って試してみましたが、SQL構文エラーになってしまいました。
【例03】
ODBCデータソースを使いたくない場合、一応、「ADO(ACEエンジン)+OLEDB接続+Range.CopyFromRecordsetメソッド」にて単純にフォルダ指定のみで、SQLでデータを取り出せます。(列名を取り出すコードが別途に必要ですが。)
以下、その例です。これも、D:\1 というフォルダの中のCSVファイルをリレーションしながら吸い込みます。なお、列名を取り出すコードは割愛してあります。
※注意!!
このACEエンジンを使う場合、Excelのバージョン2007以降かもっとあとのバージョンがインストールされていないといけなかった気がします。2003までしか入ってないパソコンでは、これは動きません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
' ' Sub tes() Dim cn As ADODB.Connection Dim rs As New ADODB.Recordset Dim strSql As String Set cn = New ADODB.Connection cn.ConnectionString = "Provider=Microsoft.ACE.OLEDB.12.0;" _ & "Data Source=D:\1;" _ & "Extended Properties=""Text;HDR=Yes;FMT=Delimited""" cn.Open strSql = "SELECT * FROM [aaa.csv] as csv1 inner join [bbb.csv] as csv2 on csv1.f01 = csv2.f001" rs.Open strSql, cn, adOpenDynamic, adLockOptimistic, adCmdText Range("A1").CopyFromRecordset rs End Sub ' ' |
======================
以下、ODBCデータソースを作る際のおおまかな手順です。
★ そのフォルダを「ODBCデータソース」のひとつとして設定する(複数のテキストファイルを置けますし、区切り文字なども別々に設定できます。)
参考Web記事
『ODBCのText DriverとExcelとを使ってCSVファイルをSQLで検索・抽出する』
★ そのフォルダに、カンマ区切りのテキストファイルを配置
★ カンマ区切りのファイルの列名行の指定や区切り文字等々の設定
★ そのフォルダに、スペース区切りのテキストファイルを配置
★ スペース区切りのファイルの列名行の指定や区切り文字等々の設定
★ Microsoft Queryからカンマ区切りのテキストファイルを読み込んでみる
★ それをマクロの記録にしてみる(QueryTableオブジェクトのみ)
★ VBAを書き換えてスペース区切りのテキストファイル吸い込んでみる。
★ VBAのSQLを書き換えて、絞り込んでみる
★ マクロで生成されたプログラム例:バージョン2010の場合(このコードだとカンマ区切りしか吸い込めませんでした)
※SQLでWHEREを使えば絞り込み吸い込みができます。
※「& Chr(13) & "" & Chr(10) &」などは消しても大丈夫です。
※事前のODBCデータソース登録は要らないかも?です。(もしエラーが出たらやってください。)→後日、やはり必要と判明しました。何もしなくてやれることはないので、以前に設定したことを忘れていただけのようです。(思い出せませんでしたが・・・)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
' ' Sub Macro2() ' ' Macro2 Macro ' ' With ActiveSheet.ListObjects.Add(SourceType:=0, Source:=Array(Array( _ "ODBC;DBQ=C:\USERS\USER01\DESKTOP;DefaultDir=C:\USERS\USER01\DESKTOP;Driver={Microsoft Access Text Driver (*.txt, *.csv)};DriverId=27" _ ), Array( _ ";Extensions=txt,csv,tab,asc;FIL=text;MaxBufferSize=2048;MaxScanRows=25;PageTimeout=5;SafeTransactions=0;Threads=3;UserCommitSyn" _ ), Array("c=Yes;")), Destination:=Range("$A$1")).QueryTable .CommandText = Array("SELECT ttt.a, ttt.b, ttt.c, ttt.d" & Chr(13) & "" & Chr(10) & "FROM ttt.txt ttt") .RowNumbers = False .FillAdjacentFormulas = False .PreserveFormatting = True .RefreshOnFileOpen = False .BackgroundQuery = True .RefreshStyle = xlInsertDeleteCells .SavePassword = False .SaveData = True .AdjustColumnWidth = True .RefreshPeriod = 0 .PreserveColumnInfo = True .ListObject.DisplayName = "テーブル_ttt_からのクエリ" .Refresh BackgroundQuery:=False End With End Sub ' ' |
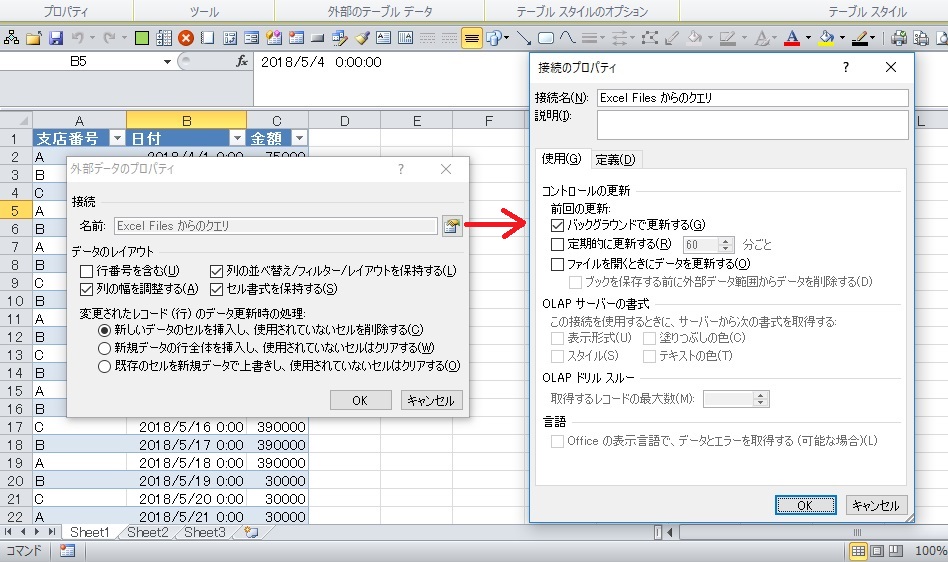
※自動書き込みされる細かい設定とダイアログボックスの対応状況の図
(『Excelで使うMySQL データ分析編』のP272の図を引用しました。)

上図はバージョン2000のものですが、バージョン2007以降などでも似たような設定ダイアログがあります。
例えば2010の場合は、「結果の表を右クリック→テーブル→外部データのプロパティ」で、下図のようになりますので、同じような設定箇所を探します。
★ C:\USERS\USER01\DESKTOP\ttt.txt の中身の例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
' ' a,b,c,d A1,1,2,0.24 B1,2,4,0.5 E4,1,5,3.55 C1,2,5,0.4 e4,5,3,0.02 p2,3,4,0.57 C2,5,4,0.8 B7,2,7,0.5 ' ' |
★ Excel2000の場合01(2010でのコードをまんまで使ったテスト)
上記の内容が、「D:\1」というフォルダにある場合です。
※事前のODBCデータソース登録は要らないかも?です。(もしエラーが出たらやってください。)→後日、やはり必要と判明しました。何もしなくてやれることはないので、以前に設定したことを忘れていただけのようです。(思い出せませんでしたが・・・)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
' ' Sub Macro3() ' ' Macro2 Macro ' マクロ記録日 : 2019/10/7 ユーザー名 : a ' With ActiveSheet.QueryTables.Add(Connection:=Array(Array( _ "ODBC;DBQ=D:\1;DefaultDir=D:\1;Driver={Microsoft Text Driver (*.txt; *.csv)};DriverId=27;FIL=text;MaxBufferSize=2048;MaxScanRows=8;Pa" _ ), Array("geTimeout=5;SafeTransactions=0;Threads=3;UserCommitSync=Yes;")), _ Destination:=Range("A1")) ' .CommandText = Array( _ ' "SELECT `ttt`.a, `ttt`.b, `ttt`.c, `ttt`.d " & Chr(13) & "" & Chr(10) & "FROM `ttt.txt` `ttt`") .CommandText = Array( _ "SELECT * FROM `ttt.txt` `ttt`") .Name = "ttttxt からのクエリ" .FieldNames = True .RowNumbers = False .FillAdjacentFormulas = False .PreserveFormatting = True .RefreshOnFileOpen = False .BackgroundQuery = True .RefreshStyle = xlInsertDeleteCells .SavePassword = True .SaveData = True .AdjustColumnWidth = True .RefreshPeriod = 0 .PreserveColumnInfo = True .Refresh BackgroundQuery:=False End With End Sub ' ' |
★ Excel2000の場合02
(直接、バージョン2000で「マクロの記録」で作ったコードを少し書きかえ。
カンマ区切りではなくて、TAB区切りとスペース区切り。)
上記の内容が、「D:\TEXTDB」というフォルダにある場合です。
カンマ区切りをから、TAB区切りとスペース区切りのファイルを作ってやりました。
TAB区切りとスペース区切りの両方・・・。
なんか2000だと特に設定してなくても、TAB区切りとスペース区切りの両方も読めてしまいました。なんかの間違いかもしれませんけど・・・・。
※事前のODBCデータソース登録は要らないかも?です。(もしエラーが出たらやってください。)→後日、やはり必要と判明しました。何もしなくてやれることはないので、以前に設定したことを忘れていただけのようです。(思い出せませんでしたが・・・)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
' ' Sub Macro2tab01() ' ' Macro2 Macro ' マクロ記録日 : 2019/10/8 ユーザー名 : a: ' 「TAB区切りのテキストファイルを吸い込む。 ' ' With ActiveSheet.QueryTables.Add(Connection:= _ "ODBC;DSN=D_txtdb_tab;DefaultDir=D:\TEXTDB;DriverId=27;FIL=text;MaxBufferSize=2048;PageTimeout=5;" _ , Destination:=Range("A1")) .CommandText = Array( _ "SELECT ttt_tab01.a, ttt_tab01.b, ttt_tab01.c, ttt_tab01.d" & Chr(13) & "" & Chr(10) & "FROM ttt_tab01.txt ttt_tab01" _ ) .Name = "D_txtdb_tab からのクエリ" .FieldNames = True .RowNumbers = False .FillAdjacentFormulas = False .PreserveFormatting = True .RefreshOnFileOpen = False .BackgroundQuery = True .RefreshStyle = xlInsertDeleteCells .SavePassword = True .SaveData = True .AdjustColumnWidth = True .RefreshPeriod = 0 .PreserveColumnInfo = True .Refresh BackgroundQuery:=False End With End Sub Sub Macro3space01() ' ' Macro3 Macro ' マクロ記録日 : 2019/10/8 ユーザー名 : a ' 「スペース区切りのテキストファイルを吸い込む。 ' ' With ActiveSheet.QueryTables.Add(Connection:= _ "ODBC;DSN=D_TXTDB;DefaultDir=D:\TEXTDB;DriverId=27;FIL=text;MaxBufferSize=2048;PageTimeout=5;" _ , Destination:=Range("A1")) .CommandText = Array( _ "SELECT ttt_space01.a, ttt_space01.b, ttt_space01.c, ttt_space01.d" & Chr(13) & "" & Chr(10) & "FROM ttt_space01.txt ttt_space01" _ ) .Name = "D_TXTDB からのクエリ" .FieldNames = True .RowNumbers = False .FillAdjacentFormulas = False .PreserveFormatting = True .RefreshOnFileOpen = False .BackgroundQuery = True .RefreshStyle = xlInsertDeleteCells .SavePassword = True .SaveData = True .AdjustColumnWidth = True .RefreshPeriod = 0 .PreserveColumnInfo = True .Refresh BackgroundQuery:=False End With End Sub ' ' |
※自動書き込みされる細かい設定とダイアログボックスの対応状況の図
(『Excelで使うMySQL データ分析編』のP272の図を引用しました。)
上図はバージョン2000のものですが、バージョン2007以降などでも似たような設定ダイアログがあります。
例えば2010の場合は、「結果の表を右クリック→テーブル→外部データのプロパティ」で、下図のようになりますので、同じような設定箇所を探します。
★ もう少し扱いやすく変形させたもの
OSの「ODBCデータソース」の画面で設定した内容が、以下のようなモノだったとして。
「データソース名:c_text-tbl」
「そのフォルダのパス:C:\text-tbl」
OS、Office、のバージョンが異なってもエラーにならないと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
' ' Sub Macro4tab01() ' ' Macro2 Macro ' マクロ記録日 : 2019/10/8 ユーザー名 : a: ' 「TAB区切りのテキストファイルを吸い込む。 ' Macro2tab01() を少し作り変えたもの ' ' Dim s_ODBCsrcName As String Dim s_ODBCsrcPath As String s_ODBCsrcName = "c_text-tbl" 'OSの「ODBCデータソース」の画面で設定した「データソース名」 s_ODBCsrcPath = "C:\text-tbl" 'その「データソース名」のデータソースのフォルダのパス With ActiveSheet.QueryTables.Add(Connection:= _ "ODBC;DSN=" & s_ODBCsrcName & ";" & _ "DefaultDir=" & s_ODBCsrcPath & ";" & _ "DriverId=27;FIL=text;MaxBufferSize=2048;PageTimeout=5;" _ , Destination:=Range("A1")) .CommandText = Array( _ "SELECT txt01_comma.a, txt01_comma.b" & Chr(13) & "" & Chr(10) & "FROM txt01_comma.txt txt01_comma" _ ) .Name = "D_txtdb_tab からのクエリ" .FieldNames = True .RowNumbers = False .FillAdjacentFormulas = False .PreserveFormatting = True .RefreshOnFileOpen = False .BackgroundQuery = True .RefreshStyle = xlInsertDeleteCells .SavePassword = True .SaveData = True .AdjustColumnWidth = True .RefreshPeriod = 0 .PreserveColumnInfo = True .Refresh BackgroundQuery:=False End With End Sub ' ' |
★UTF-8、UTF-8(BOM付き)のテキストファイルを⇒Shift-JISに変換する関数。
「Call Utf8ToSjis01(ファイルパス)」みたいな記述で使います。
以下の参考ページをもとに、ちゃんと変数宣言をしたかたちに作り替えました。
ただ、
「v_SplitRow = Split(s_AllText, vbCrLf)」
の行で、改行コードをvblfか、vbcrか、などが流動的なので、
ちゃんとした修正が必要かもしれません。
参考Webページ
https://daitaideit.com/vba-utf-8-transform/#mokuzi2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
' ' '########################################################## 'UTF-8、UTF-8(BOM付き)のテキストファイルを⇒Shift-JISに '変換する関数。 'Call Utf8ToSjis01(ファイルパス) 'https://daitaideit.com/vba-utf-8-transform/#mokuzi2 '########################################################## Function Utf8ToSjis01(FilePath As String) Dim s_AllText As String Dim v_SplitRow As Variant Dim l_Cnt01 As Long Dim l_Cnt02 As Long '変換したいテキストファイルのファイルパスを作成 ' Dim FilePath ' FilePath = ThisWorkbook.Path & "\TEST.txt" ' FilePath = "d:\1\bbb_utf8.csv" 'UTF-8もしくはUTF-8(BOM付き)のテキストファイルを読み込み With CreateObject("ADODB.Stream") .Charset = "UTF-8" .Open .LoadFromFile FilePath s_AllText = .ReadText .Close End With 'UTF-8もしくはUTF-8(BOM付き)以外を読み込んでしまった場合は終了 For l_Cnt01 = 1 To Len(s_AllText) If Mid(s_AllText, l_Cnt01, 1) <> Chr(63) Then If Asc(Mid(s_AllText, l_Cnt01, 1)) = 63 Then Debug.Print "中止--※ソースが『 UTF-8もしくはUTF-8(BOM付き)』以外だったため。" ' MsgBox "中止" Exit Function End If End If Next '改行毎にデータを分ける。 v_SplitRow = Split(s_AllText, vbCrLf) '↑(※どの改行コードかわからないので、 ' 事前に1つのファイルとかで試す。) ' あるいは、自動チェックのコードを追記する) ' v_SplitRow = Split(s_AllText, vbCr) ' v_SplitRow = Split(s_AllText, vbLf) 'Shift-JIS形式でテキストファイルへ出力 Open FilePath For Output As #1 For l_Cnt02 = 0 To UBound(v_SplitRow) Print #1, v_SplitRow(l_Cnt02) Next Close #1 Debug.Print "完了" End Function ' ' |
- 投稿タグ
- 「ニセモノ」への道, 「本物」に近づくために, AccessVBA, Accessの独学, ADO/DAO, ExcelSQL, ExcelVBA, Excelの独学, Excel操作の基礎, Excel連携VBA, MicrosoftQuery, ODBC, SQL, インポート, データ管理の基礎・Excelの基礎ではなく, パソコンでの自動化, マクロ, リレーション, 独学, 自動化
