★★★★★★★★★★★★ Excelの真の基礎~効率を良くする作表のルール・基本手順(ちょっと詳細版)~Excelやパソコンを単なる紙と電卓の延長としてではなく、真のコンピュータとして使うために~Microsoft Queryやピボットテーブルを使えるようにするために。~
※まだ書きかけです。すみません。
※間違ってたらすみません。
※メモ書きなので、自分でも意味不明な箇所も多いです
目次
★ ご注意(必ずお読みください)
★ はじめに
★ 実際の作表操作
(01)「オートコレクト」機能のOFF
(02)基本、1つのシートに、表は1つだけとします。
(03)「セルの結合」は絶対に、一か所も使ってはいけません。
(04)表のA1セルは列名を入れます。B1から右のセルもすべて列名で埋めます。列名の空白は絶対に作りません。
(05)基本的には、空白行も空白列も1つも作ってはいけません。
(06)「一つの表には2種類の名前がある(名づけ箇所が2か所ある)」ということを事前に理解しておきます。
(07) 1種類目の表の名前を決めます(シート名の「タブ」にて。MicrosoftQueryやDAOやADO用)。
(08)表の名前に「プレフィックス(接頭語)」を付けます。
(09)名づけの例
(10)列名を書き込み、列名の抜けは絶対に作らない
(11)連番の列を最低1つ、作ります(初期状態に、すぐに並べ替えできるように)。
(12)日付の列を最低1~3つ、作ります。
(13)月度、年度、などの値は別の列を設けて、日付の列をもとに関数で出します。
(14)各列、データの型を決めます。(セルの書式設定で表示形式を決めます。)
(15)【★★★超重要!!】各列、最初の10行目までの列に、データの型の違うデータを入力しないようにします。
(16)【★★★超重要!!】各列の「日本語入力モード」を決めていきます。
(17)ピボットテーブルで集計したい=列名や行名にしたい、項目を全部横方向に列名としてさらに追加していきます。
(18)顧客名簿のなどの重要な住所の場合は、「丁目」も「番地」も「枝番」も全部、1列ずつに分けます。ハイフンなどは入力しません。
(19)できた表に2種類目の名前を付けます(「名前の定義」にて。ピボットテーブル半自動化用。)。
(20)罫線や数式、セル書式は、必要のない箇所には入れないほうが面倒が無くて良いです。数式や書式はやむをえなくてもそれ以外は使わないほうが無難です。(特にVBAでUsedRangeを使いたい場合を想定して)
※Shift+TABキー、もしくは、Homeキー、Homeキー+TAB数回、を押すと、目次付近に戻れます。
★ ご注意(必ずお読みください)
この中の(08)、(09)、(16)、(18)、は、ちょっとややこしいので、もし難しく感じたら、「テスト段階」のうちは無視してもいいです。Microsft Queryやピボットを使いこなせるようになってから実施してみてください。
ただ、本番になったら、これらも守るほうがあとあとがラクになります。特に、扱うテーブルの数やクエリ(Microsft Queryの結果表)の数が増えたら必須となってきます。
それ以外の番号のモノは小学生でもパソコンが好きな子ならできます。中高生なら間違いなくできます。
また、全部が重要ですが、中でも重要なのは (17) です。
それこそが、「無駄なVBAプログラム」や「無駄な関数」を激減させる「モト」となりますので・・・。
この設定を行うことで、Excelは、データの入力されたところを自動的に「表」として認識してくれるようになります。
表の中に、多少の空白セルがあっても、「列名に空白セルが全く無く、かつ、まったくの空白の行さえなけれれば」、Excelは、データの入力された範囲を、すべて、一つの「表」として自動認識してくれるようになります。
もう少し言うと、その表を「システムテーブル」として自動認識してくれるようになります。
「システムテーブル」はMicrosoft Query を使いやすくし、それがデータを管理する効率をすごく高めます。また、ピボットやVBAプログラミング(特にDAO、ADO操作)をする際にも効率を高めてくれます。
ですので、是非、この基礎を覚えて使ってください。
初心者の方におかれましては、本来は、「何故そうするのか?」の理由も覚えたほうが良いとは思いますが、でも最初は難しくてちんぷんかんぷんだと思いますので、「深い理由は考えずに、やるべきことだけやってみる」という方向で作業してみてください。
ここに書いてあることはちょっと詳しすぎるかもしれないので、どこかで、もっと簡略にしたやり方を記事にしたいとも思っています。それができたときはそちらをご参考にしてみてください。
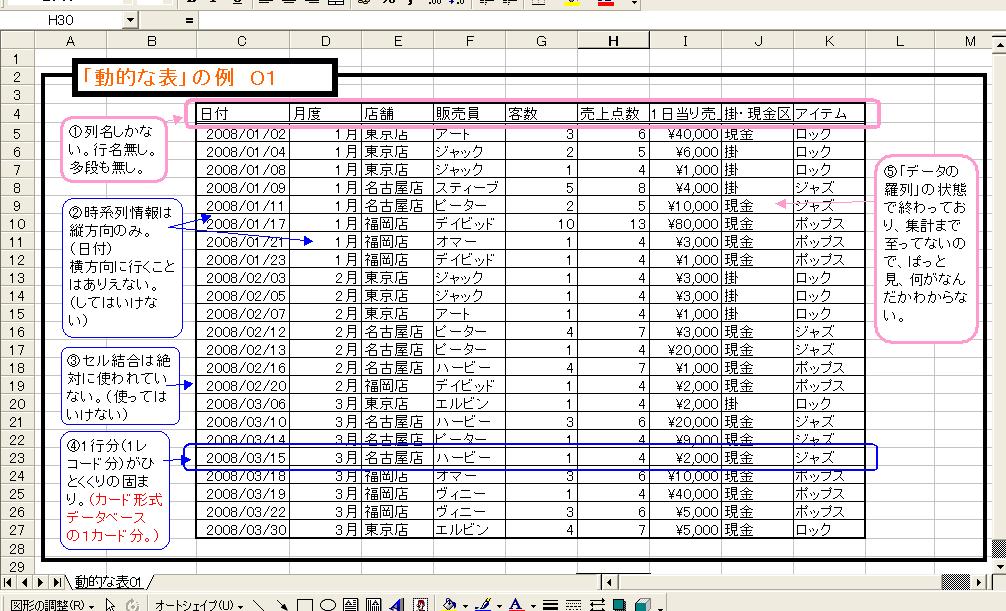
下図のような「形」の表を作ります。
図ではフキダシの説明を入れるために表の外側(上側と左側)に空白セルがありますが、本記事の方法としては、それらを無くして上と左に詰めた状態で作成します。
★ 実際の作表操作
(01)「オートコレクト」機能のOFF
「オートコレクト」の機能は、英単語の頭文字を勝手に大文字にしたりしてくれます。
英単語ではなく、メールアドレスやホームページアドレスなども同じです。
「mymailadd01@i.softback.jp」なら「Mymailadd01@i.softback.jp」になってしまうし、「http://www.abcd1234.com」なら「Http://www.abcd1234.com」になってしまいます。
これは例えば「顧客名簿に入力したメールアドレスやホームページアドレスなどが、無効なものに勝手に書き換えられてしまう」ということを意味します。メールアドレスやホームページアドレスは大文字と小文字が区別されるので、例えば「小文字でないといけない文字が大文字になっていると」エラーとなります。
つまり、お客様に出したメールはほぼ全部戻ってきてしまうし、ホームページも開けなくなるということです。(ソフトによっては、ホームページアドレスは大丈夫の場合もあるようです。ただ、大文字小文字を区別されるのは、メールアドレスやホームページアドレスだけではありませんのでやはり注意が必要です。)
データ管理の基礎においては、「オートコレクト」の機能は、多くの場合「セル結合」以上に「害」にしかなりませんので、あらかじめ切っておきます。まず無いと思いますが、でも、どうしても使いたい場面が出てきたら、その時だけ、使うようにします。でも使い終わったら、エラー回避のために、必ずOFFに戻しておきます。
(なお、「セル結合」のほうが「オートコレクト」よりは使う場面は多いと思います。帳票作成や「データ管理の基礎の外側での場面(基礎ではなんともならないところ)」などです。ただし、それ以外の場面では使うことは「害」になりやすいので原則禁止です。)
(02)基本、1つのシートに、表は1つだけとします。
(03)「セルの結合」は絶対に、一か所も使ってはいけません。
(04)表のA1セルは列名を入れます。B1から右のセルもすべて列名で埋めます。列名の空白は絶対に作りません。
そこに表の名前を入れてしまうと、便利な機能の「Microsoft Query」が使えなくなってしまい、たくさんの「無駄なVBAプログラムや関数」を書く羽目になってしまいますので・・・。
(05)基本的には、空白行も空白列も1つも作ってはいけません。
ただ、一番上の行(列名)、もしくは、一番左の列(例えば連番やIDの列)、さえ、全セルすべて同じデータ形式でしっかりと埋まっていれば、その範囲内は、部分的にデータが入ってなくてもOKです。
つまり、
「1列分は列名のセルだけが埋まっているだけであとはすべて空白セル」
とか
「1行分は連番列(ID列)のセルが埋まっているだけであとはすべて空白セル」
という形はOK、ということです。
逆に、
「列名も無いし1列まるごと抜けている」
「具体的なデータはあるけど、列名だけが抜けている」
「1行丸ごと抜けている。連番列やID列も抜けている。」
「1行分の具体的なデータはあるけど、連番列(又は ID列)だけが抜けている」
ということはNGとなります。
(06)「1つの表には2種類の名前がある(名づけ箇所が2か所ある)」ということを事前に理解しておきます。
1つの表には、名前を付ける箇所が、「2種類(2か所)」あります。
これは、Excel2000以降の全バージョンで共通です。(現行の最新は2016です。2000より前の97もかも?未チェックですが。)
※最重要のご注意※
このお話は、(05)までに書きましたとおり、A1セルから横一行が、すべて「列名」で埋まっている必要があります(「動的な表」の形)。かつ、その表をもとに数百の切り口で、かつ、VBAプログラムを使わずに自動集計したい場合に限ります。
なお、この2か所(2種類)以外の箇所での名づけ・・・、例えばA1セルやその他のセルなどに表の名前を入力する場合は、主に、「もうこれ以上計算はしない・最終提出版」という時にしたほうが無難です(もちろん絶対ではありませんが・・・)。理由は、A1セルなど、「セル」による表の名づけは「集計やリストアップの効率化」には(原則としては)まったく寄与しないからです・・・。(基本、プログラムを書かずとも、表の名前を使うことで自動的にデータをひっぱってきたり、複数条件での自動集計や自動リストアップをしたりすることができます。でもそれが「セル」で名付けしてしまうとできなくなります。あるいは非常に困難になります。集計コストが「時間・金額ともに」2倍から100倍に膨れ上がります。2倍のコストになっただけでも大変なことになる場合がありますのでご注意ください。プログラムで対処する際も、無駄なプログラムを大量に書く羽目になり、コストが増大します。これはバージョン2016でも2000でも同じです。)
では続けます。
1ヵ所目は各シートの「タブ」での名づけです。
これは「Microsoft Query」という超便利な機能を使うために付けます。「Microsoft Query」はシート名で表を管理する仕組みになっているからです。シート名で表と表をVlookup関数のように紐付けさせたりします。その他にも便利な機能が使えますが、全部、シート名単位で操作します。(詳しくは後述します。)
2ヵ所目は「名前の定義」の機能での名づけです。
こちらはピボットテーブルを使いやすくするために付けます。ピボットテーブルの列や行が増減しても、それをExcelが自動認識してくれるようにできます。
そうすることでピボットテーブル側で、ソースの表の列や行が増減してもデータ範囲を再設定せずにすみます。
行が増えても列が増えても、はたまた、そんなことをいちいち考えなくても、常に「更新」だけをしていれば、常に最新の集計結果が得られます。
注意点としては、2つともの名前をまったく同じにしてしまうとトラブルの原因となりますので、1文字でもいいので変えるか、もしくは、もっと分かりやすいように何か、例えばプレフィック=接頭語(後述)などを付け加えることです。
例えば1か所目(シート名)で「顧客マスタ」というシート名にしたら、2か所目(名前の定義側)では、「pvtsrc顧客マスタ」とかにします。(「pvtsr」は適当に自分で好きに作っていいものですが、この場合は「ピボットソース」ということを表しています。)
1ヵ所目で「T顧客マスタ」にして、2か所目で「ps顧客マスタ」という風にしてもOKです。(※「ps」は「pvtsrc」をさらに略して見やすくしたかたちです。)
なので、全体的に見たときは、例えば、
・実表の場合は「シート名」に「T」、
・仮想表の場合は「シート名」に「Q」、
・ピボットテーブルのソースの場合は「名前の定義」に小文字で「ps」
という風に、名前の先頭に付ける・・・、という感じでもOKです。
「仮想表」とは、「MicrosoftQueryを通じての絞り込み結果や集計結果の表(1つのシートに1つの仮想表)」のことですが、Accessだと「クエリ」、オラクルやSQLServerだと「ビュー」、と呼ばれているものです。
なお、2ヵ所目の「名前の定義の機能を使う方法」は、ピボットに対してだけなら・かつ・Excel2007以降でなら、「テーブル機能」というものを使っても同じようなことができます。なので、テーブル機能の中で名付けしても一応OKです。
ただ僕個人的には、どのExcelファイルも古いExcelでも動くようにしたいので、自分が作るシステムやファイルの中では、テーブル機能はやむを得ない場合以外は使いません。(たまーに使います。また、データをくれた相手が使っていた場合とかはもちろん使います。)
理由は「将来、それが原因で色々とエラーやトラブルが起こるかもしれない、ということを考えるのが面倒くさい」からです。普段使わない機能を使ってエラーが生じるなら、平常は最初から使わずにいて、もし使った場合にはエラーの原因を特定しやすくする、というかたちです。
「エラーを少しでも減らす・解決をできるだけ早くする」には、操作や処理を統一したほうが速いので、「自分にとっての全シーン」において、あまり意味の大きくない機能はできるだけ混在させないようにしています。これは業種や職種等々で変わってくると思います。
「そこまで考えるのも逆に面倒くさい」ということでしたら、テーブル機能側でピボットテーブル用の名前を付けてもOKです。
(07) 1種類目の表の名前を決めます(シート名の「タブ」にて。MicrosoftQueryやDAOやADO用)。
ポイント
・表の名前はシート名でつける(Microsoft Query で扱えるようにするために)
・名前の先頭に「プレフィックス(接頭語)」を付ける。手入力データの表なら「T_」(Tとアンダーバー)、「Microsoft Query」の結果表なら「Q_」(Qとアンダーバー)など。(次項参照。前項も必ず参照してください。)
・A1セルから横1行には絶対に表の名前を書かない。列名しか書かない。
※ここまでの、「1つのシートに表は1つだけ」とし、かつ、「セルの結合」は絶対使わないようにし、かつ、「表の名前をA1セルではなくてシート名のほうでつける」理由は、そうするとその表を「システムテーブル」としてExcelが扱ってくれるからです。
表をExcelに「システムテーブル」として扱ってもらえると、「Microsoft Query」でも扱うことができ、「リレーション」を組んだりできますし(=「SQL」を使うことができますし)、あと、VBAプログラミングの中で「DAOやADO」といった「ミドルウェア」を使うことができる(=閉じたExcelファイルのデータをネットワーク越しでもローカルでも 好き勝手に自由に読み込むことができる)ようになります。(※「ローカル=自パソコン内」と思ってください。)
これが本当にデータ管理の効率を上げます。
無駄なVBAや関数をできるだけ書かなくて済むようになります。
なおかつ(VBA無しで)、Excelを「ただの紙と電卓の延長」としてだけ使う従来の使い方だけでなく「真の”コンピュータ”」として使う使い方もプラスできるようになります。それによって、データ管理効率が2~100倍以上になります。
ですので、そのために、「1つのシートに表は1つだけ」とし、かつ、「セルの結合」は絶対使わないようにし、かつ、「表の名前をA1セルではなくてシート名のほうでつける」いった基本中の基本を守るようにします。
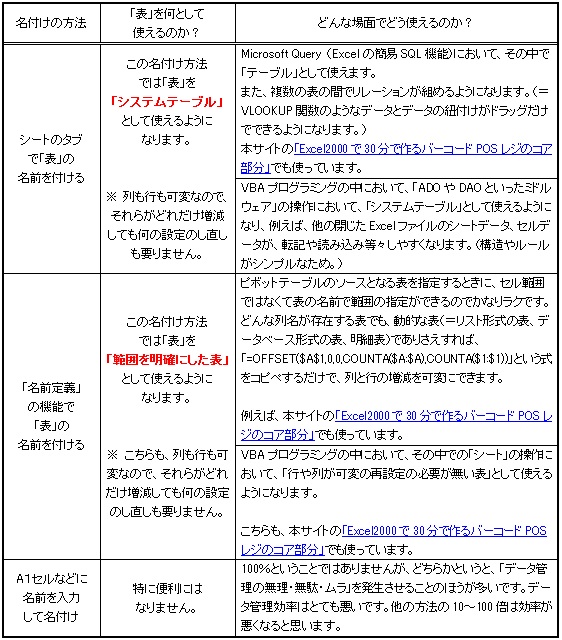
また、表の名付けとしては、「名前の定義」で付ける表の名前もありますが、これはピボットテーブルのソースとして表を指定するときに使える名前です。VBAプログラミングの中で使うときにも使えます。
以下に、表の名付けの方法とその方法ごとのメリット、あるいは、従来のA1セルに名前を入力するデメリット等を、簡単に表にまとめてみましたので、下図もご参考にしてください。
ちなみにですが、ExcelのみならずAccessやMySQLでも使える、「DAOやADO」といった「データ操作に特化した独立した機能」があるのですが、それを使うときにも「シート」を「システムテーブル」として扱えます。
そしてそれを扱う場合にも、「普通のVBAと同じように」ループ処理ができる・・・のですが、「DAOやADO」では、なんと、その際に、「セルアドレスベース」ではなくて「列名」ベースでループ処理ができるようになります。読み込みだけでなく、書き込みもできるようになります。(しかも、SQLも使えるようになります!!ただ、Excelの場合はなぜかレコードの削除ができませんが。でも、削除できないことはデータベースの世界ではそう大したことでない場合も少なくないです。あえて削除をしないで削除フラグを立てておくことで、逆に何かヒントを得たり不正を見つけたりができるので。たいていの人は画面からデータが見えない=データが消滅したと思い込むのですが、実は消えずに残ってて、不正を見つけやすくなります。)
で、「列名ベース」でループ処理ができると・・・、
「新しい列がいくつ追加されてもプログラムを変える必要がない。」とか、
「既存の列をどの位置に移動させようともプログラムを書き換える必要がない。」とか、
「新しい追加設定もいらない。」とか、
「新しい列も列を挿入した瞬間から、その列も列名ベースで処理できる。」、
・・・といった大変便利な面があります。
セルアドレスではなく、列名でピンポイントに書き換え指示が出せるため、そのような便利なことが生まれます。
参考記事
「Excel2010で、開かれていない閉じたままのブック・Excel(xls)データをできるだけ速く読み込む方法(DAOにて)」
https://euc-access-excel-db.com/tips/ct07_se/ct075010_ac2ktips/readbydao
【表の名前の付け方の詳細説明】
表の名前はシートの名前(下のほうのタブのところ)で付けます。
「Sheet1」を好きな名前に書き換えることによって付けます。
「Excelの真の基礎」では、この表の名前はとても重要です。
「Microsoft Query」を使うときにこのシートの名前でリレーションをするからです。
(リレーション=Microsoft Query の場合、ドラッグ一発で引数無しに VLOOKUP関数を使うような紐付け作業をすることを指します。内部結合等。2016の「リレーションシップ機能」と操作は同じです。でもこちらは20年も前からExcelで普通に使えていた機能です。なぜか広まってきませんでした。)
また、A1セルには絶対に表の名前を入れたりはしません。
というのも、A1セルの部分の1行は表の列名を書き込む場所だからです。
そこに表の名前を入れてしまうと、「Microsoft Query」が使えませんので、Excelを真のコンピュータとして使えず、永遠に「単なる紙と電卓の延長として」でしか、使えなくなってしまうので・・・。(「Microsoft Query」が使えなくなるというよりは「システムテーブルとして使えなくなる」という感じです。なので、便利な「DAOやADO」、も使えなくなってしまいます。
表の名前を付けるタイミングは作表の一番最初でもいいし、データの入力完了後でもOKです。
データの入力完了後のほうが表の内容を表す名前にしやすい場合も多いですので。
ただし、Microsoft Query や ピボットテーブルを利用する前までにはしっかりと決めておきます。
そして、一度決めたら、絶対に変えない、ということがエラーを減らします。これが結構大きなポイントです。
タイプミスしたとしても、もう、一度決めたら変えません。
ついでに言うと、ファイルの置き場所も、一度決めたら絶対に変えないようにします。
この2つを途中で変えると「エラーの連鎖・連発地獄」につながって、データ管理の効率が著しく落ちるからです。
なので、逆に言ったら、名付けは慎重にやります。
(だたし、初心者の方はいきなりそんなことを言われても難易度が高すぎてしまうと思いますので、初心者の方は「記号はアンダーバー以外使わない」と「数字を名前の先頭に使わない」「半角カタカナは使わない」ということだけ覚えて、あとは自由につけてもいいと思います。操作に慣れるにしたがって、これ以降に書いてある「プレフィックス」のこととか、色んなことを少しずつ考えていくようにしてみてください。
Excelでデータ管理効率が大きく落ちる、最もよくある原因の1つは、「各種の ”名前” やファイルの置き場を途中で変えてしまうこと」です。その場合、本当に面倒くさいことになります。せっかく効率を上げようとして色々とやっていることが、この2つのことのために、「すべて台無しになる」ことも少なくありません。
これは Microsoft Query やピボットテーブル を利用する場面だけではありません。
セルリンクの利用や各種基本操作でも同じ事です。
兼任社内SEさんはもちろん、一般ユーザーさんににとっても、「エラーが出た時にそれを出ないように改修する作業」は、本来のお仕事の時間を奪う本当に無駄なものなので、必ずこのことは守っておきます。
以上、名付けのタイミングや名前の変更等々については、次項の「プレフィックス(接頭語)」も同じです。
(08)表の名前に「プレフィックス(接頭語)」を付けます。
なお、Microsoft Query を使うときに、シートの名前に、実データ(=手入力した表=実表)か、それともMicrosoft Query を使って出した結果表(=抽出表=仮想表)かを区別するために、プレフィックスを必ず付けます。
例えばですが、
手入力した表ならシートの名前の先頭に「T_」、
Microsoft Query を使って出した結果表(抽出表=仮想表)なら「クエリ(Query)」の意味で「Q_」と、
いずれも半角英数で付けるのもいいと思います。
そのほか、意味あい的に近いものを漢字の1~3文字くらいで付けるのもいいと思います。
プレフィックスのあとには半角か全角でアンダーバーを付けると見やすくなって作業がしやすいです。
なお、このように、名前の先頭に付ける認識・区別用の短い文字列を「プレフィックス」とか「接頭語」、「接頭辞」などをといいます。
プレフィックスを付けることで良いのは、Microsoft Query を使うとき、例えば、「Microsoft Query の画面でどのシートを扱うかを決める場面」等々で操作しやすくなるからです。(下図参照)
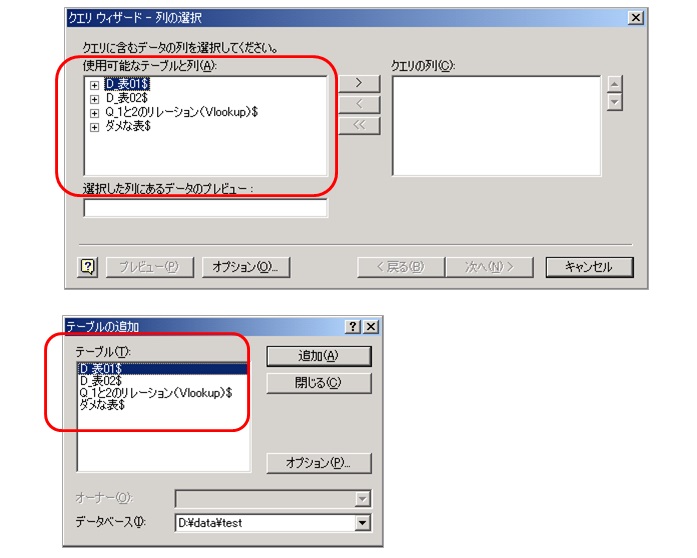
例えばそのシーンでは、上図のようにシート名(=表の名前)の先頭の数文字で並び順が決められます。
記号、数字、半角アルファベット、カタカナひらがな、漢字、といった感じで並びます。
なので、逆に言うと、プレフィックスを付けておかないと、このような画面が出てきた時にすぐに判断がつきづらいので、操作に手間取ってしまいます。
特に、シートの数が増えてくると、スクロールして表を探すことになるのですが、その時も、実データかクエリか、それとも同じ集計目的の表同士か、などがわかるほうがやりやすいです。
なので、作業の効率化のためにも、プレフィックスを必ず付けます。
以上、細かいことのように思えるかもしれませんが、慣れてしまえば無意識にやれることなので、是非、覚えておいてください。
【プレフィックスの例】
「T_」や「Q_」のほかに、そのあとに数字を付けるのもいいです。
「01」とか「02」とか「0101」「0102」「9901」とか、何らかの用途別、目的別、あるいは、集計作業やリストアップ作業ごとに順番に数字でも表現するという意味です。
例えば「01」をアイテム別+期間別の集計、「02」をアイテム別+期間別のリストアップ、・・・といった意味にするとか、あるいは、単純に、作ったもの順に番号でかたまりとして管理し、そのあとに漢字で「顧別ア別期別集計」など、なんとなく意味がわかるようにするとか・・・。
とにかく「T_」や「Q_」、数字、等々で各種画面で関係性のあるもの同士が近くに位置して、いろいろ選択操作がしやすくすることが主の目的です。
(09)名づけの例
例えば、「2006年以前にインテリア関連の商品を買ったお客様の中で、2007以降インテリア関連の商品を買っいない・・・、つまり買い替えや買い足しをしてないお客様をリストアップしたい」といった目的の場合は、例えば次のようにシートに名前を付けます。
「T_0101_06年以前_インテリア関連売上明細」とか、
「T_0101_07年以降_インテリア関連売上明細」とか、
「Q_0101_06年以前_インテリア関連買替え無し顧客分売上明細」といったような、名前の付け方をします。
※すべての表に顧客IDの列がある形となります。
で、そのほか、もしこのリストアップを他にもいつでも流用できる、システム的な利用をしたいなら、次からは、以下のような名前に変更し、いつでも流用できるようにします。
「T_以前_売上」とか、
「T_以降_売上」とか、
「Q_以前_買替え無し顧客分売上明細」、
といったような、名前の付け方をし、「T_以前_売上」や「T_以降_売上」のデータ内容は変わっても、列名さえ同じなら、どんなアイテムの計算やリストアップでもできるようにしておきます。
いきなり、具体的にはイメージしづらいと思いますので、他の場所での事例等みながら、意味をつかんでいただけたらと思います。
※ピボットのソースとなる実データのシートは、シートのタブにて「TPS_というプレフィックスを付けるのもいいかもしれません。「T」とつけることで「実データ」ということを示し、「PS」で「PivotSource(ピボットのソースの表)」という意味を表せます。ピボットの場合、「名前の定義」の機能でもピボット専用の表の名前を設定しますので、それと区別するために、最初に「T」という文字を使います。もしくは、「実データだよ」という意味の何か文字を別途使いしても良いと思います。
名前の定義のほうでピボット専用の名前を設定する場合も同じように、実データと区別できるプレフィックスを付けると良いと思います。「N(Nameの頭文字)」とか「ND」をプレフィックスの一番先頭に付ければ、「名前」とか「名前の定義(定義=Definition)」といったことが判別できます。ですので、「NDPS」とか「Ndps」とか付ければ、「”名前定義の機能の側の”、ピボットソースの表の名前」と判別できます。
(10)列名を書き込み、列名の抜けは絶対に作らない
一番上の行に列名を書き込みます。
列名に抜け(=空白セル)を作ってしまうと、そこで表が2つに分かれるのか何なのか、Excelは判断できなくなってしまいます。
ですので、ピボットテーブルやMicrosoft Queryを使うときにエラーになってしまって使えなくなります。
ですので、列名は絶対にしっかりと埋め、空白は作らないようにします。
(11)連番の列を最低1つ、作ります(初期状態に、すぐに並べ替えできるように)。
必要に応じて、いくつかの連番の列を作ります。
複数の連番の列を作るときは、「連番01」とか「連番02」など、必ず名前を少しずつ変えます。
でないとのちのちピボットテーブルやMicrosoft Queryなどでエラーが出ると困るので・・・。
なお、連番の列を作ることは、他人から何らかのExcelファイルをもらった際にも、一番最初にやります。全シートを見て、必要に応じで連番を付けます。これも理由は「初期状態に、すぐに並べ替えできるように」ということです。
(12)日付の列を最低1~3つ、作ります。
本当に最低限、「売上日付」と「入力日付」の2つは作ります。
必要に応じて、「更新日付」などの他の列も作ります。
(13)月度、年度、などの値は別の列を設けて、日付の列をもとに関数で出します。
「売上日付」をもとに、月度、年度、などの値を算出します。
参考記事
「学生さんや集計初心者のためのピボットデモ01」
ダウンロード(サンプルxlsファイルあり)
https://euc-access-excel-db.com/mag2charge/pos/for_gakusei_etc_pivot_demo01.lzh
Lzhに同梱のWordファイルの説明書をPDF化したもの
https://euc-access-excel-db.com/mag2charge/pos/pivot_demo01.pdf
目次は→こちら
はじめてピボットテーブルを触る人向けです。
日付の列がたった一つがあれば、次のようなことが簡単に集計できます。
というサンプルが入っています。
・数日後ごと(3日ごと、など)の集計
・1週間ごと(7日ごと)
・月ごとの集計
・月度ごとの集計(締め日などに関数を使いますが定型なのでコピペだけで処理します)
・年ごとの集計
・年度ごとの集計(締め日などに関数を使いますが定型なのでコピペだけで処理します)
時間の列がたった一つがあれば、次のようなことが簡単に集計できます。
・時間ごとの集計
・分ごとの集計
(14)各列、データの型を決めます。(セルの書式設定で表示形式を決めます。)
1列分を選択し、セル書式設定にて、入力する値の「表示形式」を設定します。
データを入力する際は次項を参考にして、数値を入れるはずの列に絶対に日本語や英語などを入力しないようにします。
入力する値は、各列、同じ系統の値に統一します。
でないと、各種場面で無駄なエラーを多発させることになってしまいますので・・・。
各列、同じ系統の値に統一するために、そのまた次の項目のとおり、日本語入力モードも各列に設定しておきます。
(15)【★★★超重要!!】各列、最初の10行目までの列に、データの型の違うデータを入力しないようにします。
そのために、前項の(14)を確実にやっておきます。
どうやらExcelは、ある列のデータの型を、「最初の5行だか10行だか(多分5行)に入力された値を見て勝手に決める」らしいようですので・・・。
(これは「システムテーブル」として使う場合だけです。Microsoft Query(=QueryTableオブジェクト)、ADO、DAO、での操作が関係してきます。通常の一般操作には基本的には関係ありません。でも、効率化を図りたいなら絶対に守らねばならないことです。)
最初の5行が数字だけならその列は「数値型」、日付ばかりなら「日付型」、文字列(日本語など)ばかりなら「文字列型」・・・、という感じで勝手に判断するらしいです。
(実際に「本当に5行分なのかどうか?」は確実なチェックをしてないのですみません。ご自分でもチェックしてみてください。繰り返しますが、これは「システムテーブル」として使う場合だけです。Microsoft Query(=QueryTableオブジェクト)、ADO、DAO、での操作が関係してきます。
この「自動判断」は、各列にめちゃくちゃな値が入るとエラーの原因となり、列の入力しなおし、シート(表)の作り直しなどを余儀なくされますので、各列のデータの型は必ず揃えます。(一回でも「この列は文字列型の列だ!」と判断されてしまうと、5行目以降を全部数字にしたり、あとで1行目から全部数値を入力しなおしても、その列は「数値型とみなされずに文字列型のまま」と判断されるようです。簡単に認識させなおす方法があるのかもしれませんが、今の僕にはわかりません。)
特に、Microsoft Query を使う時も、リレーションをさせる際にこれが原因で「リレーションさせる列のデータ型が違う!」みたいなエラーになることがあります。
(もしエラーになったら、リレーションに使う列やその他の怪しい列(もしくはシート丸ごと)をどこかにいったんコピぺしてから削除し、コピペした内容で、怪しい行が無いかチェックします。(たとえば数値型の列に文字列やなぜか全角の数字が入っていたなど)
怪しい行のチェックが終わったら、モトのシートに新しい列を挿入して同じ列名で列を復元し、そこにもとのデータを「値のみ」で貼り付けるとよいかもしれません。)
※ そのため、ひな形のファイルを作って、「数値型」「日付型」「文字列型」などの列をあらかじめ複数作っておき、その列の列名をつけるだけ、というような形をとったり、それらのひな型の列を、作業するExcelファイルに貼り付ける、というような形をとると良いと思います。
参考Webページ
[PRB] DAO の OpenRecordset を使用すると Excel の値として NULL が返される
https://support.microsoft.com/ja-jp/help/194124/prb-excel-values-returned-as-null-using-dao-openrecordset
「現象」と「原因」を読んでみます。「Excelが最初の数行で自動的に列のデータの型を決めている」ということの「本当の理由」ではないかもしれませんが、ただ、このようなことが原因であろうエラーが出るときがあります。特に、Microsoft Queryでリレーションを結ぶときです。リレーションを結ぼうとしている列と列のデータ型が違うのでリレーションを組めません」といったようなエラーとなってしまいます。
(16)【★★★超重要!!】各列の「日本語入力モード」を決めていきます。
各列、「入力規則」の機能にて、「コントロールなし、オン、オフ、無効、ひらがな、全角カタカナ、半角カタカナ、全角英数字、半角英数字、」などを確定していきます。
理由は3つあって、ひとつは入力時に、たとえばTABキーなどで列を右へ移動するたびに、いちいち日本語入力モードと半角英数モードを切り替えるのが面倒くさいからです。
2つめは、前項にも書いたように、Excelは最初の5行くらいを見て自動的に列のデータ型を判断・決定し、おかしな値を入力するとエラーを発してMicrosoft Queryやピボットテーブルが正常に動作できなくさせることがあります。ですので、それを回避するために、例えば「半角の数字だけを入れたい列に日本語などを入れさせない」等々のために、各列の「日本語入力モード」や「半角英数モード」等々をしっかりと決めていく必要があります。(セル書式設定とともに。)
3つめは、Excelは、たとえば色んな集計機能において、「セルの値をもとにグループ化して集計」をしてくれる・・・・のですが、しかし、次の文字は別のものとして区別されます。
「半角のアルファベットと全角のアルファベット」
「半角の数字と全角の数字」
「半角のカタカナと全角のカタカナ」
「半角のスペースと全角のスペース」
「語尾にスペースがある、なし」
など。
同じ「単語」同士でも、1文字でも違い(入力ミス)があれば、その「単語」は「異なるもの」として扱われます。
たとえば
「a1」と
「a1」
や
「タナカ」と
「タナカ」
「タナカ 」
は、すべて、それぞれ、別個のものとして扱われます。
つまり、別々にグループ化、集計がなされてしまいます。
やっかいなのは上記の例のように、数値よりも「文字列」で、たとえば「日本語と英語・数字が混ざった型番」などです。
それはもうVBAプログラムでチェックしないと防ぎようが無いと言えば無いのですが、逆に、「英語・数字のみの型番」などは、多少なりとも、VBAプログラムなしでなんとかなります。
日本語モードを「オフ」にしておくと完全な半角英数字モードになりますので入力ミスが少しでも防げます。
(※ 数値「だけ」なら自動的に半角になることが多いのでそれほど失敗はいらないのですが、ただ、油断は禁物です。誰かにファイルを渡したとたん、勝手にモードを変えられて戻ってくることもありますので。)
そのようにして、「少しでも」入力ミスを減らして、ムダな仕事を増やさないようにするために、列ごとに入力モードを決めておきます。
※例:もしカタカナのフリガナを入力する列なら、「全角カタカナ」にしておく、など。
また、集計の時以外にも、重複調査したいとき、
「a1」と
「a1」
や
「タナカ」と
「タナカ」
「タナカ 」
は、それぞれ「異なるもの」として扱われてしまい、重複の調査が正しくできません。
その時も、困ることになります。
そういった不都合を防ぐのに、あらかじめ、各列の文字の入力モードを決めておきます。
※入力ミスや重複を発見するのは、関数か重複調査の機能、ピボットテーブルなどで行います。僕はピボットとメモ用紙か、ピボットとフィルタでやることが多いです。(あと並べ替えも。) 関数は基本、使いません。
(17)ピボットテーブルで集計したい=列名や行名にしたい、項目を全部横方向に列名としてさらに追加していきます。
例えば、「従業員別売上」が知りたいなら「従業員ID」と「売上」の列を作ります。
「気温別地区別顧客別の売上と粗利」が知りたいなら「気温」、「地区区分」、「顧客ID」「売上」、「粗利」といった列を作ります。
つまり、集計で知りたいこと(クロス集計表=静的な表の列見出しや行見出しにしたい集計項目)を全部、横方向に列名にしてしまえばいいのです。
この作表の考え方は、ピボットテーブルを使いたい時だけでなく、「Microsoft Query」で便利に集計やリストアップしたいときも同じですので、是非、マスターするようにしてください。
参考記事
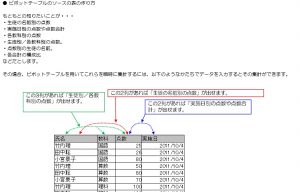
http://euc-access-excel-db.com/mag2charge/pos/pivot_src_make.htm
「ピボットテーブルの集計動作のイメージとソースの表の作り方」
【補足説明】
もともとの知りたいことが・・・
・生徒の名前別の点数
・実施日別の点数や点数合計
・各教科別の点数
・生徒別/各教科別の点数。
・点数別の生徒の名前。
・各合計の構成比
などだとします。
その場合も
・生徒の名前別の点数 →生徒名と点数の列があればいい
・実施日別の点数や点数合計 →実施日と点数の列があればいい
(点数合計も点数があればできるので)
・各教科別の点数 →各教科名と点数の列があればいい
・生徒別+各教科別の点数。 →生徒名と教科名と点数の列があればいい
・点数別の生徒の名前。 →点数と生徒名の列があればいい
・各合計の構成比 →上記のすべての列があればいい。
・生徒別+教科別+月別の点数 →生徒名と各教科名と点数の列があればいい
(月は日付の列があればそこから計算で出せるので)
という感じになります。
なので、これにあてはまる列は、ダブりの分を消して集約すれば、
・生徒名
・点数
・実施日
・教科名
の4つなので、その列を作ればいい・・・ということになります。
もちろん最初から作ってもいいですし、1つずつ、必要に応じてあとから作り足してもOKです。
ただ、リンク先の図のように、すべての列のすべての列のセルを、基本的には、すべて埋める必要があります。
多少は抜けていても集計自体はできますが、抜けていないほうが「より正確な集計」ができます。
※「より正確な集計ができる」・・・数字はウソをつくので「100%絶対」ではないですが、でもどちらかというとそういった傾向にあります。
繰り返しになりますが、この作表の考え方は、ピボットテーブルを使いたい時だけでなく、「Microsoft Query」で便利に集計やリストアップしたいときも同じですので、是非、マスターするようにしてください。
ピボットテーブルをはじめて扱う方においては、
「なんでこんな風に作る必要がある?」
と疑問に思う方も多いでしょう。
でも、それはごもっともなんですが(僕も初めての時はそうでした)、でもそれを考え始めてしまうと逆にわけがわからなくなってしまいますので、できれば・・・、
『 あまり深く考えずに ” このかたち ” をつくることだけを考えよう。そうすれば、直ちにムダな関数やVBAプログラムが激減するんだから。「調べたい項目・集計したい項目」を、列として好きなときに右方向に増やしていくだけだ。詳しいことはもう少しピボットテーブルやMicrosoftQueryのメリット・デメリット、その他の機能ことがわかってきてから調べよう。考えよう。 』
・・・という風にお考え下さるとよいと思います。
最初のうちはこのような「すべてのセルを埋める」という行為が「同じ値のセルばっかり出てくる」ので、「なんだかムダで意味不明」「2度手間3度手間・面倒くさい」に思うかもしれませんが、これこそが、
・無駄なVBAプログラムや、無駄なワークシート関数を激減させられる、超効率的な「超多角的瞬間切り替え集計」のモト、となりますし、また、
・「1回入力しただけのデータを、数十通りにも、数百通りにも ” 再利用 ” できる」ようにもなりますので、
もし、「複雑な条件でのビジネス定型集計やリストアップ」をしたいのでしたら、無駄なVBAや関数を使うよりも、是非、「こっちのほうがムダが少なくていいんだ」とご理解いただいて、本記事のような「作表」また、データ入力をしてみてください。
なお、もし、「同じ値ばっかり入力する」ということが面倒くさい、と思うのでしたら、そのときこそ、VBAプログラムや元からあるその他の便利な出来合い機能(オートフィル等々)などを使って、「同じ値をできるだけ簡単に入力する方法」を考えます。
そうすれば、「複雑な条件でのビジネス定型集計やリストアップ」に関しては、無駄なVBAや無駄な関数がそれこそ、10分の1以下から数十分の1以下になり、メンテも引き継ぎも何もかもがラクになってきます。
システム業者への外注の必要性が出てきた時も、「無駄なVBAや無駄な関数ばかりの状態」よりも、安価に済ますことができます。
(もちろん、無駄なVBAや関数ができてしまうのはエンドユーザーの責任ではまったくなく、教える側のせいです。)
なお、「どうしてもこのような作表をする理由が知りたい」、という方は、完璧な答えではありませんが、「こういう自動集計ができるので、こういう表の形にする」というイメージ的な説明が以下のリンクに先にありますので、そちらもご参考にしてみてください。

http://euc-access-excel-db.com/mag2charge/pos/pivot_calc_image.htm
(18)顧客名簿のなどの重要な住所の場合は、「丁目」も「番地」も「枝番」も全部、1列ずつに分けます。ハイフンなどは入力しません。
そのほうがのちのち無駄な関数作業が減ります。
関数を使うにしても「&」でつなげるだけで済みます。
また、町別、丁目別、番地別に、ローラー作戦をしたいような場合は、絶対に分けます。
並べ替えがそれらの項目でできるので、効率的にローラーすることをしやすくなると思います。
これはAccessでも同じです。
これはExcelが出てきて20年以上ものあいだ、「ほとんど指摘されてこなかったこと」です。
逆に、無駄な、「何かを基準に関数で番地や丁目を分ける」という面倒くさい無駄な方法ばかりが20年以上ものあいだ、教え続けられてきました。
こういうところが、私たち末端ユーザーがExcel教育者やマイクロソフト社に疑問を持つところです。
あきらかに、「丁目」も「番地」も「枝番」も全部、1列ずつに分けるほうが、その後の手間が圧倒的にかからないのに、また、地図ソフトの住所データでも内部的にはそう分かれているのに、Excelではそう教えられてこなかったのが不思議でたまりません。
失礼な言い方ですみませんが、「俺、複雑な関数が使えるよ」と自慢でもしたいのか?としか思えません。
複雑な関数が使えることなんて偉くもなんともありません。
そんなもの使わなくても済むように、最初からしておくほうが偉いに決まってます。
無駄な作業が増えないし、メンテも引継ぎもラクになりますので。
(19)できた表に2種類目の名前を付けます(「名前の定義」にて。ピボットテーブル半自動化用。)。
シートで名前を付けるのは、MicrosoftQueryを使えるようにするためでしたが、ここで付ける表の名前はピボットテーブルを使いやすくするために付けます。
「名前の定義」によって、付けます。
この「名前の定義」によって、ピボットテーブル操作において、ピボットのソースとなる表の、行や列がどれだけ増えても、データ範囲を再設定し直さなくてもよいようにできます。
これはつまり、ソースの表の 列も行も増減を「可変にする」ということになります。
ソースの表の増減が可変になれば、増えた時にはデータ範囲の再設定が不要になり、ピボット側での「更新」だけでソースの変更が反映されます。
また、減ったときは、ピボットテーブル側に無駄な「空白」の項目(アイテム)がなくなります。
そして実際には、そんなこと考えることすら必要なく、常にピボット側で「更新」さえすれば、最新の集計結果が得られます。(ただし、空白の行や列が在る、空白列名=データはあるのに列名だけ不明、ということだとエラーになります)
なお、表に名前を付ける際には、どんな表でも、(「=OFFSET($A$1,0,0,COUNTA($A:$A),COUNTA($1:$1))」という数式をコピペして使います。それだけでExcelは、表の列や行の増減を自動的に認識・自己解決してくれるようになります。
この数式では「$A$1」という風に、「A1」セルを起点としていますので、その意味でも、A1セルには列名が入っていないといけないのです。
なので、ここに表の名前を入れたりすると、列や行の増減の自動認識ができないことになってしまいます。それがデータの管理効率を著しく低下させます。
なお、2007以降の「テーブル」という機能を使っても「ピボットテーブルのソース表にするという意味においてだけ」は、同じようなことができます。
当サイトでは、バーコードPOSレジサンプルを30分で作る記事を載せていますが、そのときにVBAでこの名前の定義をした表をプログラム内で使うので、「テーブル」機能は使わずに、「=OFFSET($A$1,0,0,COUNTA($A:$A),COUNTA($1:$1))」での方法を、列や行の増減の自動認識の方法として統一していきます。
※名前の定義のほうでピボット専用の名前を設定する場合も、実データと区別できるプレフィックスを付けると良いと思います。「N(Nameの頭文字)」とか「ND」をプレフィックスの一番先頭に付ければ、「名前」とか「名前の定義(定義=Definition)」といったことが判別できます。ですので、「NDPS」とか「Ndps」とか付ければ、「”名前定義の機能の側の”、ピボットソースの表の名前」と判別できます。
他方、ピボットのソースとなる実データのシートは、シートのタブにて「TPS_というプレフィックスを付けるといいかもしれません。「T」とつけることで「実データ」ということを示し、「PS」で「PivotSource(ピボットのソースの表)」という意味を表せます。ピボットの場合、この項にもあるように「名前の定義」の機能でピボット専用の表の名前を設定しますので、それと区別するために(=「名前の定義の機能を使っていない名前だ!」と明示的に示す意味で)、最初に「T」という文字を使います。それか別途に、「実データだよ」という意味の文字を、何か使っても良いと思います。
(20)罫線や数式、セル書式は、必要のない箇所には入れないほうが面倒が無くて良いです。数式や書式はやむをえなくてもそれ以外は使わないほうが無難です。(特にVBAでUsedRangeを使いたい場合を想定して)
ここでは「MicrosftQueryで集計やリストアップをする前提」ですので、「VBAを使う前提ではない」のですが、もしかしたらVBAを使うこともあるかもしれないので、一応書いておきます。
VBAを使うときに、作った表全体を操作する場合に、「WorkSheet.UsedRange」プロパティを使うことがあると思います。
このプロパティは、「使用されたセルの一番端から端までの矩形エリア(空白セルも含む)」を選択範囲としてくれるプロパティです。
ただ、そのときに、数値や文字列が直接入力されているセルは当然としても、次のようなセルも「使用されている」とみなされてしまいます。
・数式が入っているが、IF関数などで空白セルに見せているセル。
・「標準」以外の書式設定が過去に1度でもなされてたセル(書式を標準に戻してもダメ)。
・白い塗りつぶし設定がなされいるセル。
・罫線が設定されているセル(特に淡いグレーで見分けがついにくいとか)。
・コンボボックス+関数、などの利用で、「文字色:白」の設定をしてしまったセル。
・その他
数式や「標準」以外の書式設定についてはやむを得ないとしても、そのほかの罫線や色付けなどはしないほうが無難です。(ただ、表の外側で、過去に一度でも書式設定がしてあるセルが存在すると面倒くさいことになるかもしれません。列ごとや行ごと削除してしまえばいいのですが。)
MicrosoftQueryやピボットなどで集計する際にはさほど影響ないのでそう心配は要らないのですが、VBAで何らかの操作をしたい場合は、気を付けてください。
なお、入力規則の日本語モードの設定は関係ない模様です。(入力規則については日本語モードの設定ところしか調査してません。すみません。)
参考記事
「ピボットテーブルのソースの表を、行も列も可変にして、再設定しなくても済むようにする方法 2つ(「=OFFSET($A$1,0,0,COUNTA($A:$A),COUNTA($1:$1))」とテーブル機能)」
https://euc-access-excel-db.com/tips/ct08_exceltruebasic/ct080820_make_table_rule/src01
「ピボットテーブルの集計動作のイメージとソースの表の作り方」
(00)
(00)
(00)
(00)
(00)
(00)
